
SiameseXML
Joint work with Kunal Dahiya, Ananye Agarwal, Gururaj K, Jian Jiao, Amit Singh, Summet Agarwal, Purushottam Kar, Manik Varma
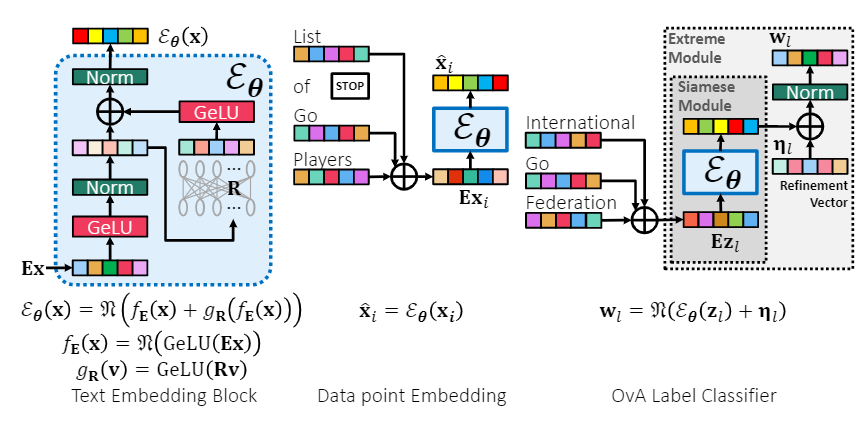
The task of deep extreme multi-label learning (XML) requires training deep architectures capable of tagging a data point with its most relevant subset of labels from an extremely large label set. Applications of XML include tasks such as ad and product recommendation that involve labels that are rarely seen during training but which nevertheless hold the key to recommendations that delight users. Effective utilization of label metadata and high quality predictions for rare labels at the scale of millions of labels are key challenges in contemporary XML research. To address these, this paper develops the SiameseXML method by proposing a novel probabilistic model suitable for extreme scales that naturally yields a Siamese architecture that offers generalization guarantees that can be entirely independent of the number of labels, melded with high-capacity extreme classifiers. SiameseXML could effortlessly scale to tasks with 100 million labels and in live A/B tests on a popular search engine it yielded significant gains in click-through-rates, coverage, revenue and other online metrics over state-of-the-art techniques currently in production. SiameseXML also offers predictions 3–12% more accurate than leading XML methods on public benchmark datasets. The generalization bounds are based on a novel uniform Maurey-type sparsification lemma which may be of independent interest.
You can watch our conference presentation video here.
Let me know what you think of this article through mail!